Tutorial: Build your custom real-time object classifier

In this tutorial, we will learn how to build a custom real-time object classifier to detect any object of your choice! We will be using BeautifulSoup and Selenium to scrape training images from Shutterstock, Amazon’s Mechanical Turk (or BBox Label Tool) to label images with bounding boxes, and YOLOv3 to train our custom detection model.
Pre-requisites:
1. Linux
2. CUDA supported GPU (Optional)
Table of Contents:
Step 1: Scraping
Step 2: Labeling
Step 3: Training
Step 1: Scraping
In Step 1, we will be using shutterscrape.py, a small Python program I wrote, to help us batch download training images from Shutterstock.
1. Installing ChromeDriver
Open Terminal, download the ChromeDriver zip file, unzip, and run chromedriver:
wget https://chromedriver.storage.googleapis.com/2.43/chromedriver_linux64.zip
unzip chromedriver_linux64.zip
./chromedriverWe will use ChromeDriver to simulate human clicks for navigating across Shutterstock’s website.
2. Installing dependencies
Open Terminal and install dependencies:
pip install beautifulsoup4
pip install selenium
pip install lxml3. Downloading script
Save shutterscrape.py in your working directory.
4. Running shutterscrape.py
1. Open Terminal in the directory of shutterscrape.py and run:
python shutterscrape.py2. Enter i for scraping images.
3. Enter the number of search terms. For example, if you want to query Shutterstock for images of “fidget spinners”, enter 2.
4. Enter your search term(s).
5. Enter the number of pages (pages of image search results on Shutterstock) you want to scrape. Higher number of pages correlate to greater quantity of content with lower keyword precision.
6. Go grab a cup of tea ☕ while waiting… oh wait, it’s already done!
After Step 1, you should have your raw training images ready to be labeled. 👏
Step 2: Labeling
In Step 2, we will be using Amazon’s Mechancal Turk, a marketplace for work that requires human intelligence, to help us label our images. However, this automated process requires you to pay the workers ~$0.02 per image labeled correctly. Hence, you may also label images manually, by hand, using BBox annotator. This section assumes that you already have the unlabeled images for training or have completed Step 1.
A. Using Mechanical Turk
0. Definitions
Requester
A Requester is a company, organization, or person that creates and submits tasks (HITs) to Amazon Mechanical Turk for Workers to perform. As a Requester, you can use a software application to interact with Amazon Mechanical Turk to submit tasks, retrieve results, and perform other automated tasks. You can use the Requester website to check the status of your HITs, and manage your account.
Human Intelligence Task
A Human Intelligence Task (HIT) is a task that a Requester submits to Amazon Mechanical Turk for Workers to perform. A HIT represents a single, self-contained task, for example, “Identify the car color in the photo.” Workers can find HITs listed on the Amazon Mechanical Turk website. For more information, go to the Amazon Mechanical Turk website.
Each HIT has a lifetime, specified by the Requester, that determines how long the HIT is available to Workers. A HIT also has an assignment duration, which is the amount of time a Worker has to complete a HIT after accepting it.
Worker
A Worker is a person who performs the tasks specified by a Requester in a HIT. Workers use the Amazon Mechanical Turk website to find and accept assignments, enter values into the question form, and submit the results. The Requester specifies how many Workers can work on a task. Amazon Mechanical Turk guarantees that a Worker can work on each task only one time.
Assignment
An assignment specifies how many people can submit completed work for your HIT. When a Worker accepts a HIT, Amazon Mechanical Turk creates an assignment to track the work to completion. The assignment belongs exclusively to the Worker and guarantees that the Worker can submit results and be eligible for a reward until the time the HIT or assignment expires.
Reward
A reward is the money you, as a Requester, pay Workers for satisfactory work they do on your HITs.
1. Setting up your Amazon accounts
- Sign up for an AWS account
- Sign up for an MTurk Requester account
- Link your AWS account to your MTurk account
- (Optional) Sign up for a Sandbox MTurk Requester Account to test HIT requests without paying - highly recommended if you are new to MTurk. Remember to link your Sandbox account to your AWS account as well.
- Set up an IAM user for MTurk and save your access key ID and secret access key for later use.
- Create a bucket on Amazon S3
- Upload your photos to the bucket, set your bucket access to public, and save the bucket name for later use.
2. Installing dependencies
Open Terminal and install dependencies:
pip install boto
pip install pillow3. Creating image list
Open Terminal in the directory where you have placed all your photos and create a list of all the filenames of your images:
ls > image.list4. Downloading scripts
Save src.html, generate.py, retrieve.py, andformat.py in your working directory.
5. Creating HIT template for Bounding Box
You can use MTurk to assign a large variety of HITs. In this section, I will go through how to set up a HIT template for drawing bounding boxes to label images, based on Kota’s bbox annotator.
- Sign in to your MTurk Requester account.
- Click Create > New Project > Other > Create Project.
- Fill in the required fields and click Design Layout > Source.
I recommend setting Reward per assignment to $0.1, Number of assignments per HIT to 1, Time allotted per assignment to 1, HIT expires in to 7, Auto-approve and pay Workers in to 3, and Require that Workers be Masters to do your HITs to No. - Paste the code in
src.htmlinto the editor and adjust the description to your needs. - Click Source (again) > Save > Preview and Finish > Finish.
- Click Create > New Batch with an Existing Project > [Your project name] and save the HITType ID and Layout ID for later use.
5. Generating HITs
- In
generate.py, changeC:/Users/David/autoturk/image.listin line 9 to the local path of your list of image filenames.
Changedrone-netofhttps://s3.us-east-2.amazonaws.com/drone-net/in line 12 to your Amazon S3 bucket name where you've uploaded your images.
Change[Your_access_key_ID]in line 14 to your access key ID.
Change[Your_secret_access_key]in line 15 to your secret access key.
ChangedroneofLayoutParameter("objects_to_find", "drone")in line 19 to your object name.
Change[Your_hit_layout]in line 22 to your HIT's Layout ID.
Change[Your_hit_type]in line 24 to your HIT's HITType ID. - (Optional) If you are using Sandbox mode, change
mechanicalturk.amazonaws.comin line 16 tohttp://mechanicalturk.sandbox.amazonaws.com.
Changehttps://www.mturk.com/mturk/preview?groupId=in lines 30 and 31 tohttps://workersandbox.mturk.com/mturk/preview?groupId=. - If you are using the normal (non-sandbox) mode, remember to charge up your account balance to pay your hardworking workers!
- Open Terminal in the directory of
generate.pyand run:
python generate.py6. Retrieving HITs
- In
retrieve.py, changeC:/Users/David/autoturk/hit-id.listin line 16 to the local path of your generated list of HIT IDs.
ChangeC:/Users/David/autoturk/image.listin line 17 to the local path of your list of image filenames.
Change[Your_access_key_ID]in line 21 to your access key ID.
Change[Your_secret_access_key]in line 22 to your secret access key.
ChangeC:/Users/David/autoturk/labels/in line 34 to the local path of the directory in which you plan to save the labels (.txt files) for each image.
Changedrone-netofhttps://s3.us-east-2.amazonaws.com/drone-net/in line 48 to your Amazon S3 bucket name where you've uploaded your images. - (Optional) If you are using Sandbox mode, change
mechanicalturk.amazonaws.comin line 23 tohttp://mechanicalturk.sandbox.amazonaws.com. - (Optional) If you would like to retrieve all annotation .txt files at once without visualization, comment out lines 48 to 61.
- Open Terminal in the directory of
retrieve.pyand run:
python retrieve.py7. Creating label list
Open Terminal in the directory where you placed all your labels and create a list of all the filenames of your labels:
ls > labels.list8. Converting for YOLO
You need to convert the generated labels (.txt files) into the format compatible with YOLO.
- In
format.py, changeC:/Users/David/autoturk/labels/labels.listin line 4 to the local path of your list of label filenames.
ChangeC:/Users/David/autoturk/images/in line 7 to the local path of the directory who you have placed your images.
ChangeC:/Users/David/autoturk/yolo-labels/in line 11 to the local path of the directory who you will store your reformatted labels.
ChangeC:/Users/David/autoturk/labels/in line 12 to the local path of the directory who you have placed your labels. - Open Terminal in the directory of
format.pyand run:
python format.pyB. Using BBox annotator
1. Installing BBox Label Tool
We will be using a Python program implemented with Tkinter to draw bounding boxes on our images.
2. Installing dependencies
Open Terminal and install dependencies:
pip install Pillow3. Annotating
First, move all your training images to under /Images/001 in the directory of BBox Label Tool.
Then, open Terminal in the directory of main.py and run:
python main.pyFor more information, please follow the BBox Label Tool usage guidelines.
4. Creating label list
- Open Terminal in the directory where you placed all your labels and create a list of all the filenames of your labels:
ls > labels.list5. Downloading reformatting script
Save format.py in your working directory.
6. Converting for YOLO
You need to convert the generated labels (.txt files) into the format compatible with YOLO.
- In
format.py, changeC:/Users/David/autoturk/labels/labels.listin line 4 to the local path of your list of label filenames.
ChangeC:/Users/David/autoturk/images/in line 7 to the local path of the directory who you have placed your images.
ChangeC:/Users/David/autoturk/yolo-labels/in line 11 to the local path of the directory who you will store your reformatted labels.
ChangeC:/Users/David/autoturk/labels/in line 12 to the local path of the directory who you have placed your labels. - Open Terminal in the directory of
format.pyand run:
python format.pyAfter Step 2, you should have your images labeled and ready to be trained on YOLO. 👏
Step 3: Training
In Step 3, we will be running YOLOv3, a state-of-the-art, real-time object detection system, to train our custom object detector. This tutorial assumes that you already have the labeled images for training or have completed Step 2.
0. What is YOLOv3?
Why use YOLO instead of another deep learning algorithm for object detection such as Fast R-CNN? The reason: Because YOLO is even faster.
Instead of applying the model to an image at multiple locations and scales, like conventional approaches, YOLO applies a single neural network to the full image for both classification and localization.
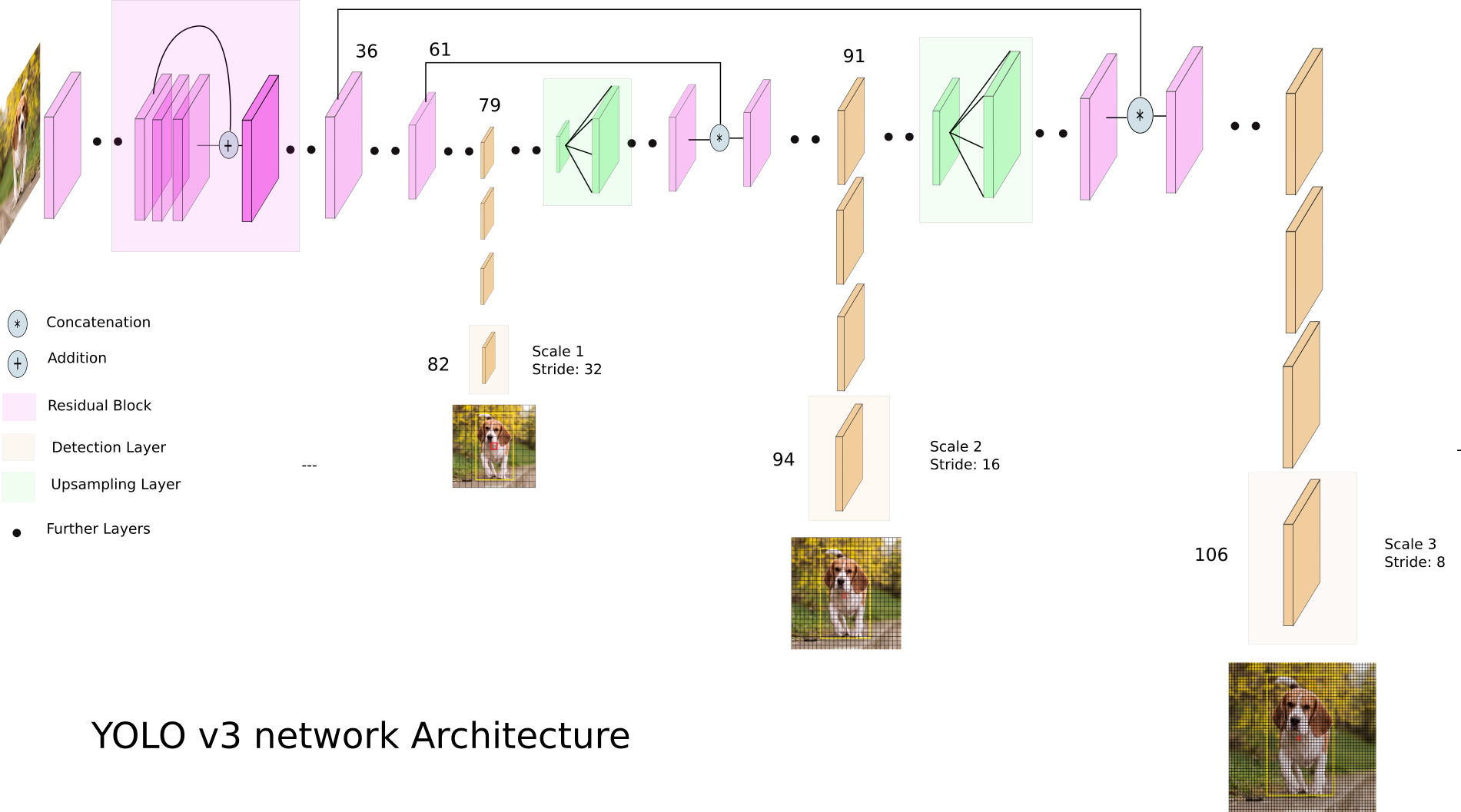
YOLOv3 uses a custom variant of the Darknet architecture, darknet-53, which has a 53 layer network trained on ImageNet, a large-scale database of images labeled with Mechanical Turk (which is what we used for labeling our images in Step 2!). For object detection, 53 more layers are stacked on top, giving us a 106 fully convolution architecture as the basis for YOLOv3. YOLOv3 attempts prediction at three scales, downsampling the size of the input image by 32, 16, and 8.
For more on YOLOv3, feel free to read the paper or this excellent blog post.
1. Installing Darknet
Open Terminal in your working directory, clone the Darknet repository, and build it:
git clone https://github.com/pjreddie/darknet
cd darknet
makeThen, run
./darknetand you should have the output:
usage: ./darknet <function>If you are using your GPU (instead of CPU) for training and have CUDA configured correctly, open the Makefile with a text editor:
gedit Makefile
(or "vi Makefile" if you are a l337 h4x0r)Then, set GPU=1, save the file, and run make again.
Remember to run make every time you make changes to files!
2. (Optional) Testing YOLO
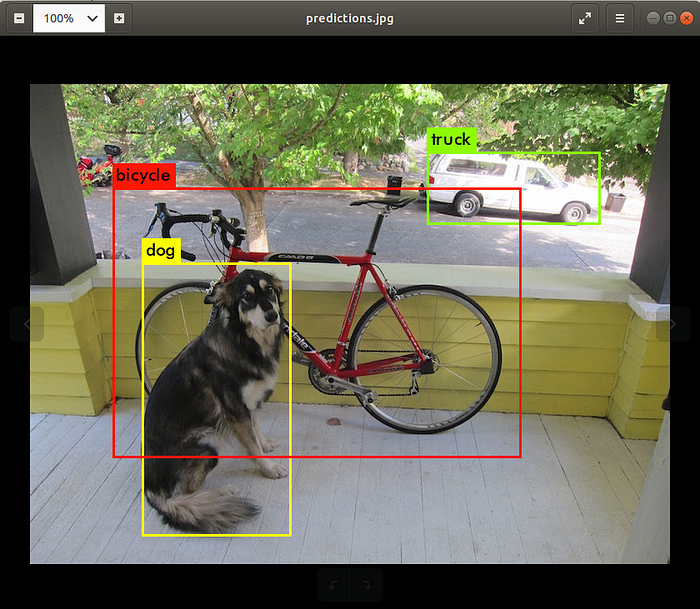
Open Terminal in the directory of Darknet, download pretrained weights, and run the detector on a sample image of a dog:
wget https://pjreddie.com/media/files/yolov3.weights
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpgYou should first see the weights being downloaded and then some output like this:
layer filters size input output
0 conv 32 3 x 3 / 1 608 x 608 x 3 -> 608 x 608 x 32 0.639 BFLOPs
1 conv 64 3 x 3 / 2 608 x 608 x 32 -> 304 x 304 x 64 3.407 BFLOPs
...
105 conv 255 1 x 1 / 1 76 x 76 x 256 -> 76 x 76 x 255 0.754 BFLOPs
106 yolo
Loading weights from yolov3.weights...Done!
data/dog.jpg: Predicted in 0.028924 seconds.
dog: 100%
truck: 92%
bicycle: 99%A visualization should be saved as predictions.jpg in your Darknet directory.
3. Creating train.txt and test.txt
We need to split our collection of images into two groups: one group for training and one group for testing. This is done so that after training, our model can later be tested with images it has never seen before during training to prevent overfitting and encourage generalization. To do this, we will be using a small Python script, split.py.
First, save split.py in your working directory.
Next, open Terminal in the directory of split.py and run:
python split.pyAfter selecting the directory of where you’ve saved your images in the pop-up GUI, you should see that two new files, train.txt and test.txt, have been created in your working directory. These files basically list the paths of the images in a 9:1 ratio of training images to testing images.
Finally, move train.txt and test.txt to the Darknet directory.
4. Downloading pre-trained weights
Save the weights for the convolutional layers to the Darknet directory:
wget https://pjreddie.com/media/files/darknet53.conv.74Before training our labeled images, we need to first define three files for YOLO: .data, .names, and .cfg.
5. Configuring .data
In your Darknet directory, create obj.data and fill in the contents with the following:
classes = 1
train = train.txt
valid = test.txt
names = obj.names
backup = backup/This tells YOLO that you are training 1 (custom) class, the paths of your training images, the paths of your testing images, the name of your class (obj.names will be created in a bit), and that you want to save your trained weights under the backup directory. These trained weights are later used to run your detector (like what we did in 2).
7. Configuring .names
In your Darknet directory, create obj.names and fill in the contents with the name of your custom class. For example, the contents of your obj.names may simply be:
fidget spinner8. Configuring .cfg
We will now create a .cfg file to define our architecture. Let’s copy a template to get us started.
If your computer has a “powerful” GPU (e.g. 4GB+), follow the instructions for yolov3.cfg. Otherwise, follow the instructions for yolov3-tiny.cfg. The tiny version has a lower accuracy but a faster processing rate.
Option 1: yolov3.cfg
Go to the cfg directory under the Darknet directory and make a copy of yolov3.cfg:
cd cfg
cp yolov3.cfg obj.cfgOpen obj.cfg with a text editor and edit as following:
In line 3, set batch=24 to use 24 images for every training step.
In line 4, set subdivisions=8 to subdivide the batch by 8 to speed up the training process and encourage generalization.
In line 603, set filters=(classes + 5)*3, e.g. filters=18.classes=1, the number of custom classes.
In line 689, set filters=(classes + 5)*3, e.g. filters=18.classes=1, the number of custom classes.
In line 776, set filters=(classes + 5)*3, e.g. filters=18.classes=1, the number of custom classes.
Then, save the file.
Option 2: yolov3-tiny.cfg
Go to the cfg directory under the Darknet directory and make a copy of yolov3-tiny.cfg:
cd cfg
cp yolov3-tiny.cfg obj.cfgOpen obj.cfg with a text editor and edit as following:
In line 3, set batch=24 to use 24 images for every training step.
In line 4, set subdivisions=8 to subdivide the batch by 8 to speed up the training process and encourage generalization.
In line 127, set filters=(classes + 5)*3, e.g. filters=1.
In line 135, set classes=1, the number of custom classes.
In line 171, set filters=(classes + 5)*3, e.g. filters=1.classes=1, the number of custom classes.
Then, save the file.
9. (Optional) Change configurations to save weights at lower iteration intervals
After you start training, you will notice that YOLO saves the weights at each hundredth iteration until iteration 900. After that, the next set of saved weights will be at iteration 10,000, 20,000, and so on. That’s a long time to wait for each checkpoint. What if you have to pause your training at, for example, iteration 19,900? You would have to resume from iteration 10,000!
To save your weights at lower iteration intervals, open detector.c under the examples directory in the Darknet directory with a text editor.
Then, edit line 138 to describe when you would like your weights to be saved. For example, change if(i%10000==0 || (i < 1000 && i%100 == 0)) to if(i%1000 == 0 || (i < 1000 && i%100 == 0)) to save the weights at each thousandth iteration after 900.
Finally, save the file and run make.
10. Training
To start training, open Terminal the directory of Darknet and run:
./darknet detector train obj.data cfg/obj.cfg darknet53.conv.7411. Waiting
How long you should train will depend on how many custom classes you’re training for, how many images you are using, your GPU, etc.
As a general guideline, stop training when your loss (the number right after your iteration number) stops decreasing after a “considerable amount of time” to prevent overfitting.
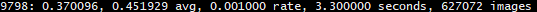
12. Testing
Wow, 11 took quite a while didn’t it? You finally realized that your loss was not decreasing significantly and decided to pause your training. Congratulations, you are ready to deploy your results!
Remember the testing images we created earlier? Finally, these images are put into good use. Move one of your images in the testing group to the directory of Darknet and rename it as test.jpg.
Next, open Terminal in the directory of Darknet and run:
./darknet detector test obj.data cfg/obj.cfg backup/obj[your-iteration-number].weights test.jpgAs the image we are testing with was not used in the training process, the results should accurately reflect how well the model has been trained.
If the results aren’t up to what you have expected, go back to 10 and continue training for just a bit longer. However, this time, instead of using darknet53.conv.74 for your training, use one of your (most recent) weights by replacing it with backup/obj[your-iteration-number].weights.
You have reached the end of the tutorial! Now, go out and see what your amazing object classifier can do. 🎉
DroneNet
If you don’t want to spend time scraping and labeling images, I’ve prepared a database of 2664 images of DJI drones, labeled with MTurk. The Github repository contains the raw and labeled images files and also retrained YOLO weights and configurations.
