2022 Top Papers in AI — A Year of Generative Models
This year, we see significant progress in the field of generative models. Stable Diffusion 🎨 creates hyperrealistic art. ChatGPT 💬 answers questions to the meaning of life. Galactica 🧬 learns humanity’s scientific knowledge but also reveals the limitations of large language models.
This article is my take on the 20 most impactful AI papers of 2022.

Table of Contents
- Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL-E 2)
- High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion)
- LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models
- An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
- DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
- Make-A-Video: Text-to-Video Generation without Text-Video Data
- FILM: Frame Interpolation for Large Motion
- YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors
- A ConvNet for the 2020s
- A Generalist Agent (Gato)
- MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
- Human-level Play in the Game of Diplomacy by Combining Language Models with Strategic Reasoning (Cicero)
- Training Language Models to Follow Instructions with Human Feedback (InstructGPT and ChatGPT)
- LaMDA: Language Models for Dialog Applications
- Robust Speech Recognition via Large-Scale Weak Supervision (Whisper)
- Galactica: A Large Language Model for Science
- Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
- Block-NeRF: Scalable Large Scene Neural View Synthesis
- DreamFusion: Text-to-3D using 2D Diffusion
- Point-E: A System for Generating 3D Point Clouds from Complex Prompts
1. Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL-E 2)
OpenAI
DALL-E 2 improves the realism, diversity, and computational efficiency of the text-to-image generation capabilities of DALL-E by using a two-stage model. DALL-E 2 first generates a CLIP image embedding given a text caption, then generates an image conditioned on the image embedding with a diffusion-based decoder.

2. High-Resolution Image Synthesis with Latent Diffusion Models (Stable Diffusion)
LMU and Runway
Stable Diffusion achieves stylized and photorealistic text-to-image generation using diffusion probabilistic models. With its model and weights open-sourced, Stable Diffusion has inspired countless text-to-image communities and startups.

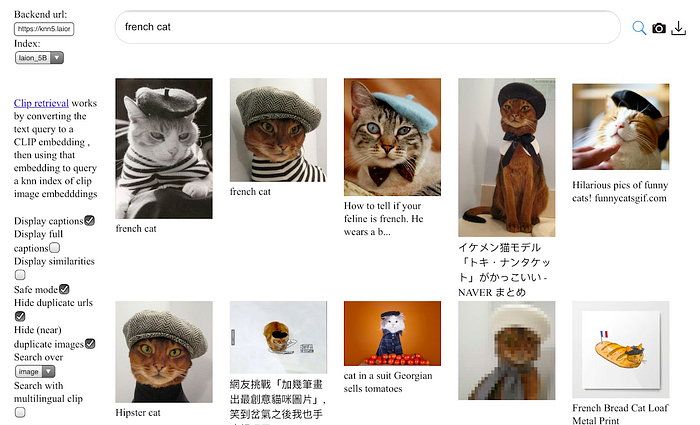
3. LAION-5B: An Open Large-Scale Dataset for Training Next Generation Image-Text Models
LAION
The LAION-5B dataset contains 5.85 billion image-text pairs that are filtered with CLIP. The dataset is being used to train models such as Stable Diffusion and even CLIP itself.
4. An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Tel Aviv University and NVIDIA
An Image is Worth One Word is a technique that converts visual concepts into “words”. For example, a user can provide several illustrations from Andy Warhol and represent Warhol’s aesthetic with the “word” <warhol>. The user can then use the “word” to prompt a text-to-image generation model (e.g. <warhol> banana).

5. DreamBooth: Fine Tuning Text-to-Image Diffusion Models for Subject-Driven Generation
by Google Research
DreamBooth is a technique that fine-tunes a text-to-image model to learn about a specific subject, in order to generate new images containing the subject. For example, a user can let a text-to-image model learn about their puppy and generate a new image of their puppy getting a haircut.

6. Make-A-Video: Text-to-Video Generation without Text-Video Data
Meta AI
Make-A-Video enables text-to-video generation by first learning text-to-image generation from text-image pairs, then learning to generate movement from unsupervised video footage.
7. FILM: Frame Interpolation for Large Motion
Google Research and UW
FILM is a frame interpolation algorithm that achieves state-of-the-art results for large motion. FILM can add slow motion to videos or create videos from near-duplicate photos.
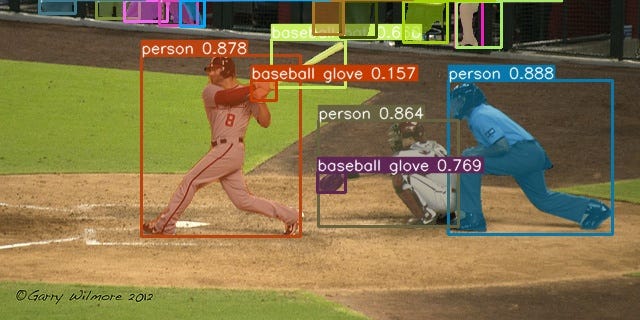
8. YOLOv7: Trainable Bag-of-Freebies Sets New State-of-the-Art for Real-Time Object Detectors
Academia Sinica
From the authors of YOLOv4, YOLOv7 sets a new state-of-the-art for object detection in terms of both speed and accuracy. P.S. My first article on Medium is a tutorial on YOLOv3.
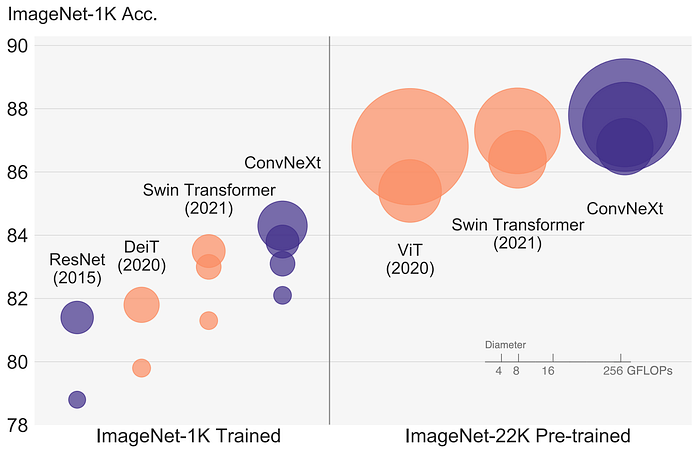
9. A ConvNet for the 2020s
Meta AI and UC Berkeley
Nowadays, Vision Transformers (ViTs) have seemly replaced Convolutional Neural Networks (ConvNets) as the state-of-the-art for image classification. In this paper, the authors take a deep dive into what makes each of the architectures perform well and propose a new family of ConvNets, called ConvNeXt, that completes favorably with ViTs.
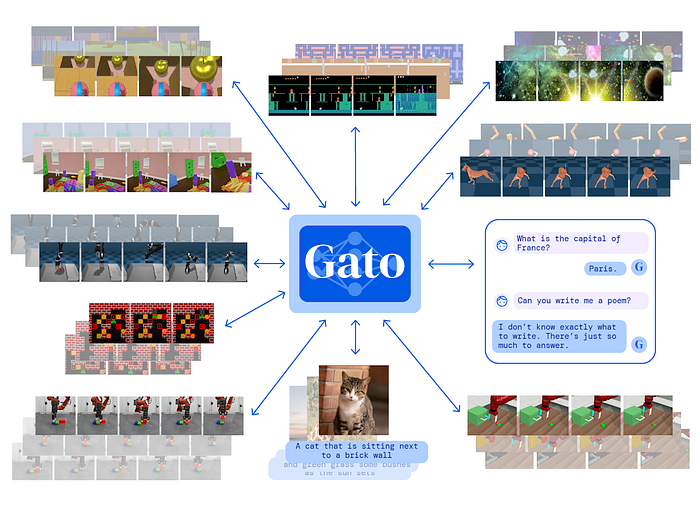
10. A Generalist Agent (Gato)
DeepMind
Gato is a multimodal agent that can play Atari, caption images, chat, and stack blocks with a real robot arm. The different modalities are serialized into flat sequences of tokens and processed by a Transformer similar to a language model.
11. MineDojo: Building Open-Ended Embodied Agents with Internet-Scale Knowledge
NVIDIA and Caltech
MineDojo is a project built on top of Minecraft aimed at advancing the training of generalist agents. The project introduces a simulation suite with thousands of open-ended tasks and an internet-scale knowledge base of videos, tutorials, wiki pages, and forum discussions.
12. Human-level Play in the Game of Diplomacy by Combining Language Models with Strategic Reasoning (Cicero)
Meta AI
Cicero is an agent that achieves human-level performance in Diplomacy, a strategy game that involves cooperation and competition with natural language negotiation. AI researchers have constantly used games, such as Go, Poker, and Minecraft, as a playground for AI agents.

13. Training Language Models to Follow Instructions with Human Feedback (InstructGPT and ChatGPT)
OpenAI
Fine-tuning language models using reinforcement learning with human feedback (RLHF) allows them to be better aligned with human intent and consequently more useful for users. Users can interact with fine-tuned models like ChatGPT through simple instructions or questions. ChatGPT gained 1 million users in just 5 days, making it one of the fastest-growing products ever.

14. LaMDA: Language Models for Dialog Applications
Google Research
LaMDA is a family of Transformer-based language models for dialog. The models are fine-tuned with annotated data to prevent harmful suggestions, reduce bias, and improve factual grounding.

15. Robust Speech Recognition via Large-Scale Weak Supervision (Whisper)
OpenAI
Whisper is a multilingual automatic speech recognition (ASR) system that approaches human-level robustness and sets a new state-of-the-art for zero-shot speech recognition. Rumors say that OpenAI developed Whisper to mine more information from videos for training their next generation of large language models.

16. Galactica: A Large Language Model for Science
Meta AI
Galactica is a large language model trained on a large scientific corpus of papers, reference material, and knowledge bases. Unfortunately, like many other language models, Galactica can hallucinate statistical nonsense, which can be especially harmful in scientific settings. Galactica only survived three days on the internet.

17. Instant Neural Graphics Primitives with a Multiresolution Hash Encoding
NVIDIA
Instant NGP speeds up the training of neural graphics primitives, such as NeRF, neural gigapixel images, neural SDF, and neural volume, to almost real-time.
18. Block-NeRF: Scalable Large Scene Neural View Synthesis
Waymo and UC Berkeley
Block-NeRF extends NeRF representations to city-scale scenes. The authors construct a large-scale NeRF for an entire neighborhood of San Francisco from 2.8 million images.
19. DreamFusion: Text-to-3D using 2D Diffusion
Google Research
DreamFusion enables text-to-3D generation of NeRF representations with a text-to-image diffusion model prior. DreamFusion indirectly optimizes the 3D model by optimizing its 2D renderings from random angles.

20. Point-E: A System for Generating 3D Point Clouds from Complex Prompts
OpenAI
Point-E speeds up text-to-3D generation of point clouds to seconds and minutes on a single GPU. Point-E first generates an image with a text-to-image model, then generates a 3D points cloud conditioned on the image with a diffusion model. Could this be the precursor of 3D DALL-E?

And that’s a wrap! 📄
This article is by no means exhaustive and there are many great papers this year — I initially wanted to make a list of 10 papers but ended up with 20! I tried to cover papers on different topics, such as generative models 🎨 (Stable Diffusion, ChatGPT), AI agents 🤖 (MineDojo, Cicero), 3D vision 👀 (Instant NGP, Block-NeRF), and new state-of-the-arts in fundamental AI tasks 🆕 (YOLOv7, Whisper). If you have any other papers that you particularly enjoyed reading this year or if you have any general thoughts on the topic, please feel free to share them in the comments below. 🙂
For the Year 2023, I look forward to seeing exponential growth in various forms of text-to-x models (text-to-video, text-to-3D, text-to-audio, text-to-…). I also hope to see improvements in the factual grounding of large language models. Oh and there’s GPT-4.
